Nel corso degli ultimi decenni, l'approccio alla gestione e archiviazione dei dati aziendali è cambiato radicalmente, guidato dalla crescita esponenziale dei volumi di dati, dalla diversificazione delle fonti e dall'evoluzione dei casi d'uso analitici.
L'evoluzione dei sistemi di gestione dati enterprise, dal tradizionale Data Warehouse al Data Lake, fino al moderno Data Lakehouse, presentano caratteristiche, vantaggi e limitazioni in ciascun approccio. Esploriamo quindi i sistemi di gestione dati fra storia e tecnologia.
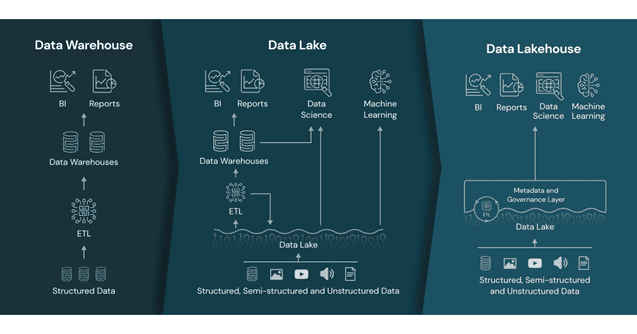
Data Warehouse: le fondamenta (1980-2000s)
Il concetto di Data Warehouse (DW) è stato formalizzato da Bill Inmon nei primi anni '90, che lo definì come "una raccolta di dati orientata al soggetto, integrata, variabile nel tempo e non volatile a supporto dei processi decisionali del management".
Un Data Warehouse è un database relazionale progettato specificamente per gestire query analitiche su grandi volumi di dati, tipicamente strutturati e provenienti da sistemi operativi aziendali (ERP, CRM, ecc.).
Caratteristiche principali:
- Schema predefinito (schema-on-write): La struttura dei dati deve essere definita prima dell'inserimento
- Modello relazionale: Utilizzo di tabelle, chiavi e relazioni per organizzare i dati
- ETL (Extract, Transform, Load): Processo rigoroso di pulizia e trasformazione dei dati prima del caricamento
- Modellazione dimensionale: Utilizzo di schemi a stella o a fiocco di neve per facilitare le query analitiche
- Costo: Richiede hardware dedicato e licenze software proprietari
Vantaggi:
- Prestazioni ottimizzate per query analitiche complesse
- Dati altamente strutturati e coerenti
- Conformità alle proprietà ACID (Atomicità, Coerenza, Isolamento, Durabilità)
- Governance dei dati robusta
Limiti:
- Costi elevati di implementazione e manutenzione
- Scalabilità limitata con crescita esponenziale dei dati
- Difficoltà nel gestire dati semi-strutturati o non strutturati
- Tempi lunghi per modificare lo schema (scarsa agilità)
- Impossibilità di supportare efficacemente casi d'uso di machine learning avanzato
Data Lake: la rivoluzione della flessibilità (2010s)
Il termine "Data Lake" fu coniato da James Dixon nel 2010, descrivendolo come un repository di archiviazione che contiene una vasta quantità di dati grezzi nel loro formato nativo, fino a quando non sono necessari.
Un Data Lake è un sistema di storage distribuito che permette di memorizzare enormi volumi di dati in formato grezzo, strutturati, semi-strutturati o non strutturati, senza necessità di definire uno schema a priori.
Caratteristiche principali:
- Schema flessibile (schema-on-read): La struttura viene applicata solo al momento della lettura
- Storage a basso costo: Utilizzo di tecnologie distribuite come HDFS, Amazon S3, Azure Data Lake Storage
- ELT (Extract, Load, Transform): Dati caricati prima e trasformati solo quando necessario
- Supporto per tutti i tipi di dati: Strutturati, semi-strutturati e non strutturati
- Architettura distribuita: Possibilità di scalare orizzontalmente
Vantaggi:
- Costi inferiori rispetto ai Data Warehouse tradizionali
- Flessibilità estrema nella gestione di vari formati di dati
- Capacità di conservare tutti i dati storici nella loro forma originale
- Capacità di supportare casi d'uso avanzati come Machine Learning e analisi in tempo reale
- Scalabilità praticamente illimitata
Limiti:
- Difficoltà nella governance dei dati (potenziale "data swamp")
- Prestazioni inferiori per query analitiche rispetto ai Data Warehouse
- Mancanza di transazionalità (non ACID-compliant)
- Complessità nella gestione degli accessi e della sicurezza
- Difficoltà nell'ottenere una visione unificata dei dati
Data Lakehouse: la convergenza (2017-presente)
Il concetto di Data Lakehouse è emerso intorno al 2017, con l'introduzione di formati di file open-source come Apache Parquet, Delta Lake (Databricks), Apache Iceberg e Apache Hudi, che hanno aggiunto funzionalità transazionali ai Data Lake.
Un Data Lakehouse combina i vantaggi del Data Warehouse (transazionalità, performance, governance) con quelli del Data Lake (flessibilità, scalabilità, supporto a tutti i formati di dati), creando un'architettura ibrida unificata.
Caratteristiche principali:
- Formati di tabella aperti: Delta Lake, Iceberg, Hudi che forniscono funzionalità ACID
- Separazione storage-compute: Cloud-native con risorse computazionali elastiche
- Metastore unificato: Catalogo centralizzato dei metadati per tutti i dati
- Multi-engine: Supporto per diverse tecnologie di elaborazione (Spark, Presto, Trino)
- Schema enforcement e evolution: Applicazione e evoluzione flessibile degli schemi
- Supporto per Business Intelligence (BI) e Machine Learning (ML): Architettura progettata per supportare entrambi i paradigmi
Vantaggi:
- Unicità della piattaforma: elimina la necessità di sistemi separati per BI e ML
- Riduzione dei costi: meno copie di dati, infrastruttura più semplice
- Prestazioni migliorate: ottimizzazioni per query analitiche sui dati nei data lake
- Flessibilità: supporto per dati strutturati e non strutturati
- Governance unificata: un unico sistema per sicurezza, audit e lineage dei dati
Implementazioni più diffuse:
- Databricks* Lakehouse Platform: Basata su Delta Lake
- Snowflake: Con le sue recenti funzionalità di supporto per dati non strutturati
- Amazon Redshift Spectrum: Estensione di Redshift per interrogare dati in S3
- Google BigLake: Layer unificato per BigQuery e Cloud Storage
- Azure Synapse Analytics: Combinazione di data warehouse e big data analytics
* Databricks - Data Evolution
© 2026 Cerved Group S.p.A. u.s.
Via dell’Unione Europea n. 6/A-6/B – 20097 San Donato Milanese (MI) – REA 2035639 Cap. Soc. € 50.521.142 – P.I. IT08587760961 – P.I. Gruppo IT12022630961 - Azienda con sistema qualità certificato da DNV – UNI EN ISO 9001:2015